We are excited to announce the start of company that will build around Polars, enabling data processing at any scale.
Backstory
What a ride…
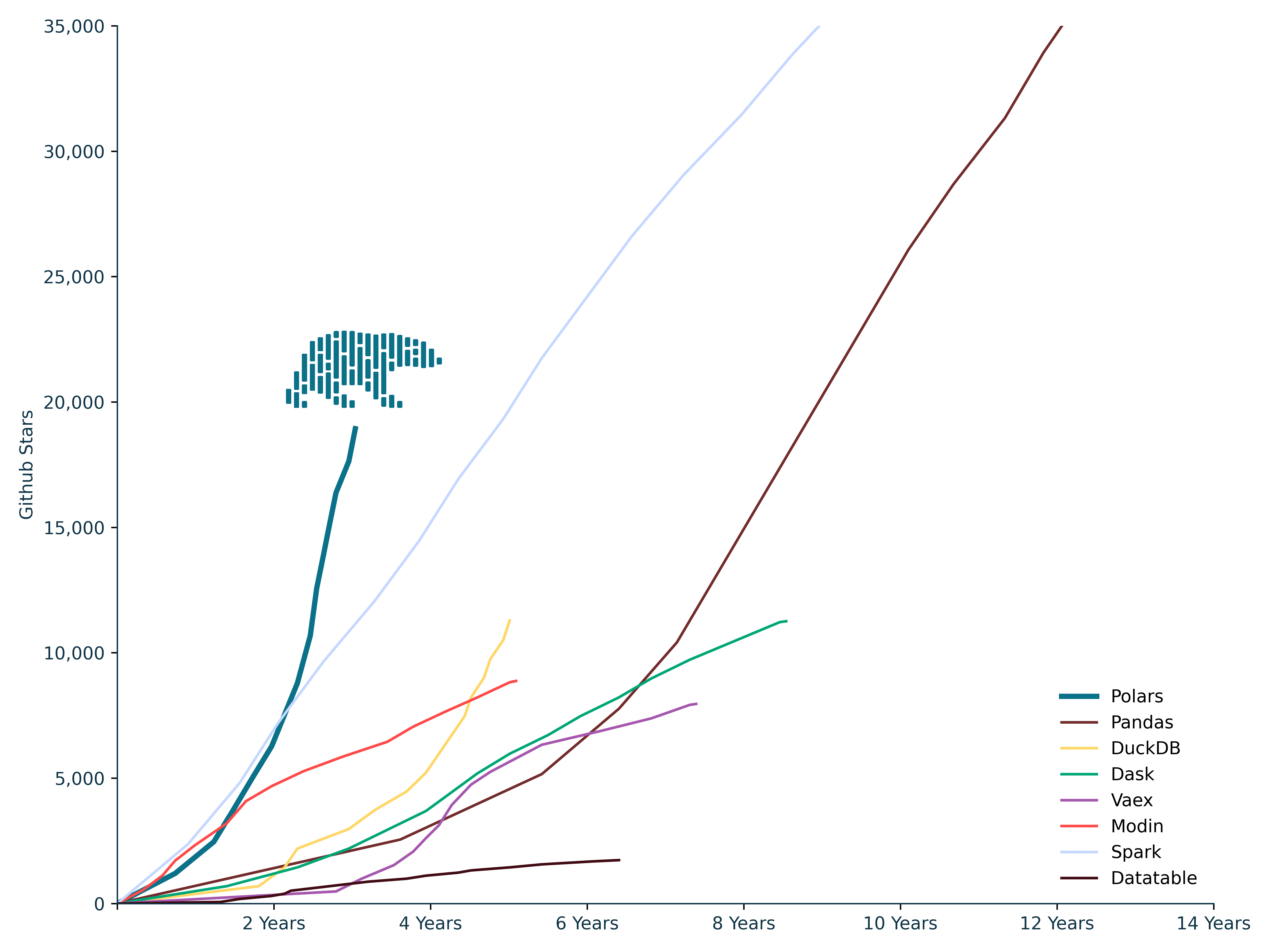
It has been 3 years (23 June 2020) since the first commit of Polars. It started as a pet project of mine, with the goal to learn more about query engines, Apache arrow and the Rust programming language. It has grown far beyond that since.
Polars has grown to one of the fastest open-source OLAP query engines [1]. And the adoption has grown beyond what I ever anticipated. In GitHub stars the project has been the fastest growing data processing project that I am aware of. At the moment of writing Polars has over 6 million total downloads and 19.000 github stars, closing in on Apache Spark and Pandas, the most popular DataFrame implementations in existence. I am very thankful for all the help from the open-source community, the users, and Xomnia, without them this blog would not have been posted.
Why
Polars has jumped in a void that has become more wide in the last 10 years. Laptops used by developers have become more powerful and more underused. DataFrame implementations implemented for single node were mostly single threaded, only utilized RAM memory and didn’t use conventional wisdom and research available in the database community.
Polars was written from scratch in Rust, and therefore didn’t inherit bad design choices from its predecessors, but instead learned from them. Cherry picking good ideas, and learning from mistakes. The main drivers for its success are:
- A strict, consistent and composable API. Polars gives you the hangover up front and fails fast, making it very suitable for writing correct data pipelines.
- OLAP query engine: I see DataFrames as a front-end on a query engine. Polars is a fast vectorized query engine that has excellent performance and memory usage. Besides that, Polars comes with a query optimizer, meaning that users can write idiomatic code and the optimizer focuses on making it fast.
- We love to work locally and put our own machine to work. This is best explained by quoting from one of our issues :)
Polars is so incredibly fast (and feature-rich) that I find myself abandoning R and its data.table package. Indeed, one guilty pleasure is to code lots and lots of steps with “lazy” data frames and then run collect() at the end — and then sit back to watch in htop as the cores on my Threadripper Pro go to work. It’s ahhhh … pretty amazing!
We started a company
We are aiming to deliver a Rust-based compute platform that will efficiently run Polars at any scale.
We believe that the Polars API can be used for both local and cloud/distributed environments. Our API is designed to work well on multiple cores, this design also makes it well poised for a distributed environment. We also believe that a Rust based columnar OLAP engine (Polars), is perfectly suited for efficient distributed computing. The (closed source) development of DataBricks’ photon engine is proof that those environments are no longer IO bound. They concluded they need C/C++ level performance and columnar memory to unblock their CPU limits.
To accelerate towards this goal, we started a company. I have asked Chiel Peters to join me as a co-founder to start a company. Chiel and I have been working at the same company (Xomnia) the past 5 years and I really trust his insights and him as a person. We successfully closed a seed round of approximately 4M$, which was lead by Bain Capital Ventures. Together we will launch Polars into its new phase and we are really excited to get started.
Polars the OSS project
The company will be built around the open-source Polars project. Our services will improve Polars’ scalability and interoperability in enterprise environments. Polars will remain MIT-licensed and the company will sponsor and accelerate the open-source development of Polars.
Short term goal
Our initial focus will be on setting up the managed environment, improving cloud connectors, caching and getting connected to companies that use Polars. I don’t want to be too specific here, as that never ages well.
We need you
We cannot do this alone, and we need both great hires and great companies to work with us.
We are hiring
You can be a part of this. If you are an experienced Rust developer with interest/knowledge in building databases, or writing fast software, please go to https://hiring.pola.rs. We are looking for +- 4 CET.
We are looking for design partners
Polars is moving fast. New features and improvements are added on a daily basis. We are looking for companies, with substantial use cases, that are using or migrating to Polars for a collaboration to learn from real world use cases and experiences. Design partners help identify potential areas for improvements, shape future plans and boost its success. If you are interested in being our partner, please contact us at info@polars.tech.
A: Appendix
The suboptimal state of DataFrame implementations can mostly be attributed to:
A.1 Ignoring database research
Efficient data processing is a hard problem. A problem that has been researched for a long time, though you wouldn’t tell if you looked at the problem from a DataFrame perspective. Almost all implementation runs your query as is and don’t do any optimization on behalf of the user. I believe a DataFrame should be seen as a materialized view. What is most important is the query plan beneath it and the way we optimize and execute that plan. The DataFrame itself is just an intermediate data structure. It is an abstraction that helps users think about their business problem, but on our side, most important is the query engine.
A.2 Implementations are written in Python.
Because Python is the host language of the most popular DataFrame implementation, Python and tools already available. This can be seen clearly with pandas. Pandas uses numpy, even though it is a poor fit for relational data processing. Numpy is great for numerical processing, but for any other data type that doesn’t fit a number (arrays, strings, structs) it requires storing boxed Python objects. This has been accepted for over 10 years. For the rust programmers; a column would be somewhat similar to Vec<Box<Mutex<dyn PythonObject>>>, but then the Mutex would be global and lock access for all objects.
Any other tool that utilizes pandas inherits the same poor data types and the same single threaded execution. If the problem is GIL bound, we remain in single threaded Python land.
A.3 Idle hardware
My laptop has 16 cores and 1TB hard disk. A DataFrame implementation should utilize that and efficiently (so no Python multiprocessing).